Tianle Wang 王天乐I am currently a first-year Ph.D. student at Purdue University, and I am fortunate to be advised by Prof. Abulhair Saparov. Previously, I completed my M.S. at UC San Diego under the supervision of Prof. Jingbo Shang. Prior to that, I obtained my B.E. from Shanghai Jiao Tong University in the ACM Honors Class. Please check my Curriculum Vitae for more information. |

|
ResearchI'm interested in LLM reasoning and planning, especially exploring how to use reinforcement learning in the post-training stage to improve the model's capability. |
|
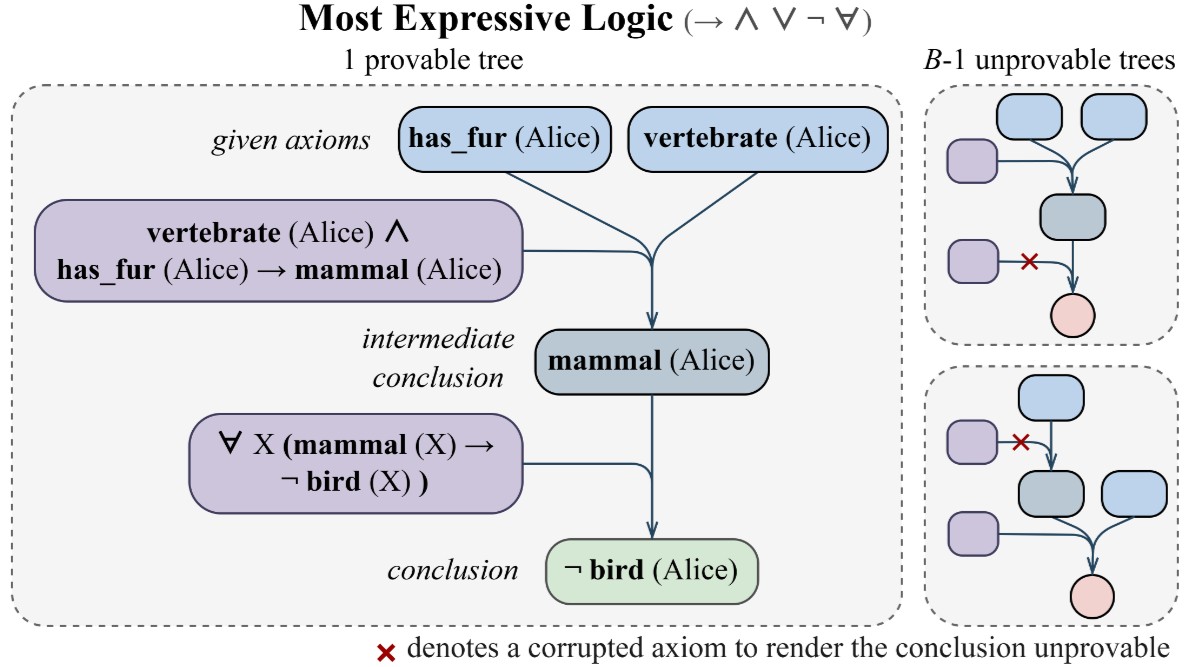
Can RL Teach Long-Horizon Reasoning to LLMs? Expressiveness Is KeyTianle Wang, Zhaoyang Wang, Guangchen Lan, Xinpeng Wei, Sipeng Zhang, GuanWen Qiu, Abulhair Saparov Preprint, 2026 arxiv / code / Create a synthetic logical reasoning environment to study RL scaling and downstream transfer under long-horizon reasoning. |
|
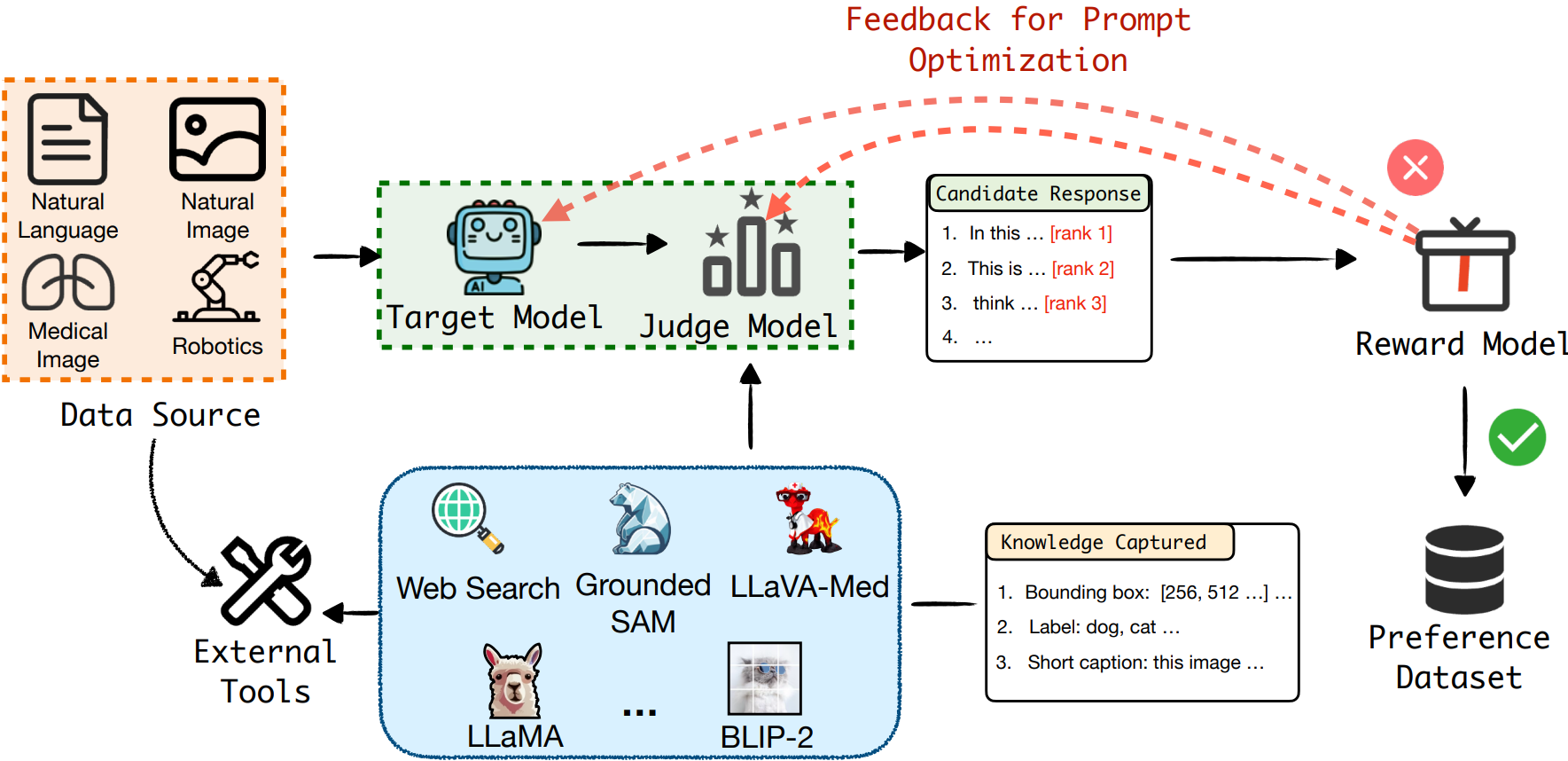
AnyPrefer: An Automatic Framework for Preference Data SynthesisYiyang Zhou*, Zhaoyang Wang*, Tianle Wang*, Shangyu Xing, Peng Xia, Bo Li, Kaiyuan Zheng, Zijian Zhang, Zhaorun Chen, Wenhao Zheng, Xuchao Zhang, Chetan Bansal, Weitong Zhang, Ying Wei, Mohit Bansal, Huaxiu Yao The Thirteenth International Conference on Learning Representations, 2025 arxiv / Build a framework to synthesize high-quality data for preference training. |
|
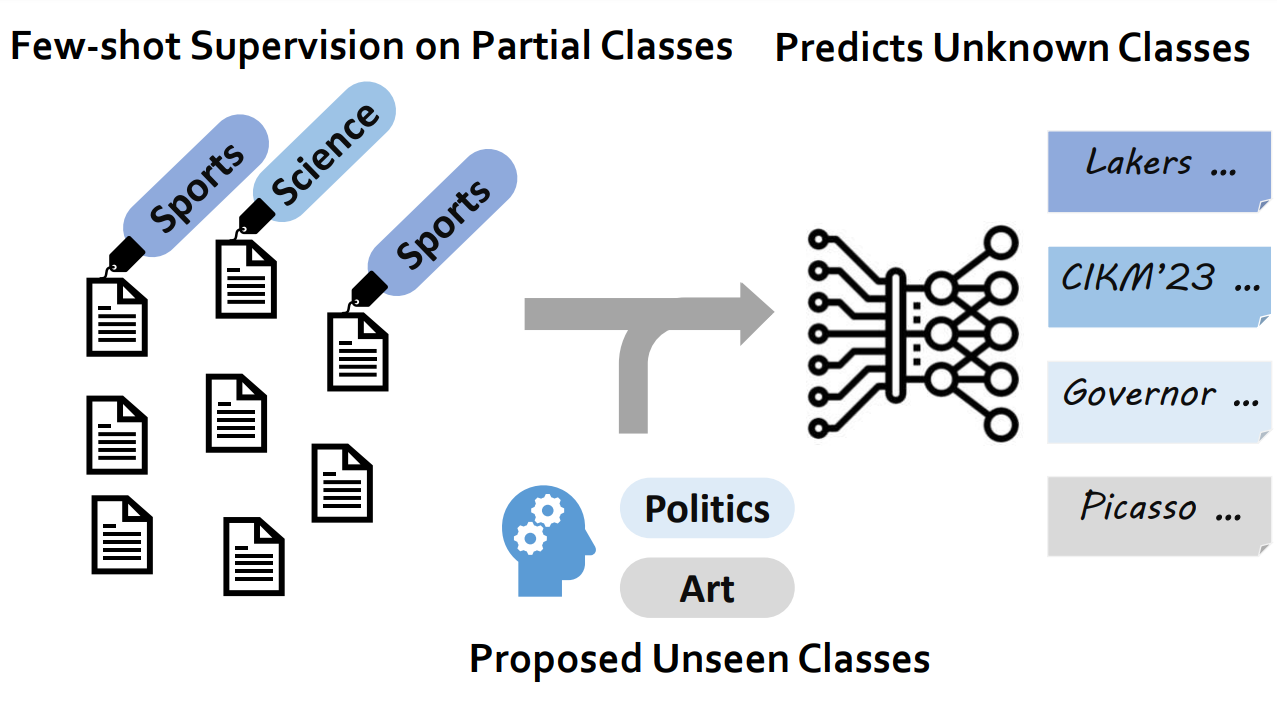
WOT-Class: Weakly Supervised Open-world Text ClassificationTianle Wang, Zihan Wang, Weitang Liu, Jingbo Shang The Conference on Information and Knowledge Management, 2023 arxiv / code / slides / Propose a novel framework WOT-Class in weakly supervised open-world text classification. |
|
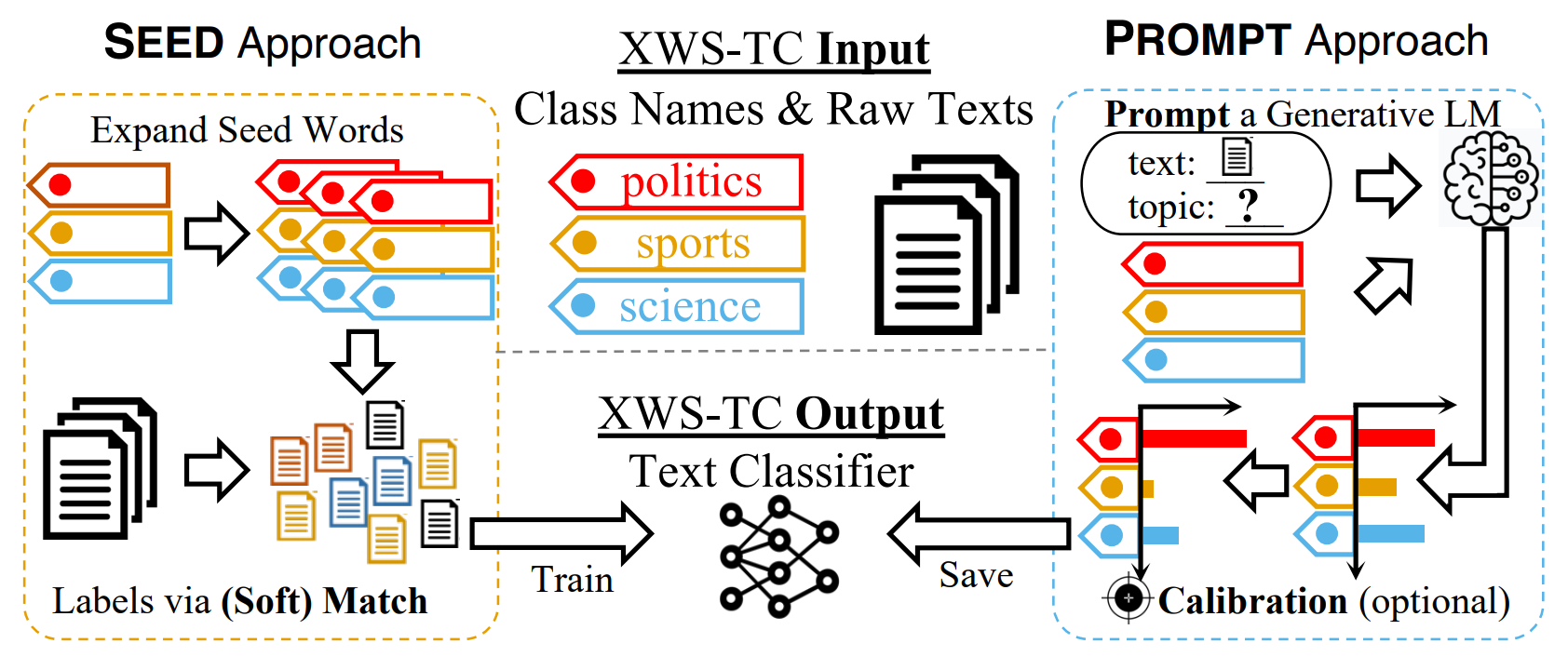
A Benchmark on Extremely Weakly Supervised Text Classification: Reconcile Seed Matching and Prompting ApproachesZihan Wang*, Tianle Wang*, Dheeraj Mekala, Jingbo Shang The 61st Annual Meeting of the Association for Computational Linguistics (Findings), 2023 arxiv / code / Developed a benchmark to compare extremely weakly supervised text classification methods. |
|
Design and source code from Jon Barron's website |